#Duplicate file cleaner code
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
HOW I PERSONALLY ORGANIZE MY DIGITAL ZINE MASTERCOPIES!
Hey zineovators, hello every'all. I am here to note down how I (PERSONALLY) fix around and assign my digitally-made zine mastercopies for easy access. This isn't meant to be a guide and it surely isn't the "correct" way to file zines, nor is this necessary, it might even be redundant for a lot of people, but this is just the way I do it. I have some really crappy guides throughout my yap session, BUT I will provide a REAL example using my own zine at the end! anyhow, let us begin! WHY DO I BOTHER?
because it makes my personal zine creation process more manageable
organization makes it less daunting for me to actually go through with the creation process
It tickles my fish brain to file and sort things, and it makes me happy to do so
so yeah, it all boils down to personal preference. I like making my digital process cleaner and a bit more streamlined, but you really don't have to follow me or use me as a standard. I just do what I do best.
That aside... TERMS I COINED AND WILL BE USING AND EXPLAINING (LIST) (yes this is based off of A/B/O but also coding)
ALPHA Mastercopy (A-Copy, Alpha copy)
BETA Mastercopy (B-Copy, Beta Copy, Physical Mastercopy)
OMEGA Mastercopy (O-Copy, Omega Copy, Assembled Mastercopy)
PRELIMINARIES!
A master copy in my own words is the original mother version of your zine that you can use to duplicate or create more copies for distribution purposes. You usually do not give a master copy away especially if you plan to make more prints of a specific zine design in the future! Also, I'm using the classic 8-page mini-zine format as an example here because...I specialize in mini-zines, lol. With that in mind, here is the portion you are waiting for.
ALPHA MASTER COPY (i.e.. RAW DIGITAL FILE)

The Alpha copy is the version of your zine that you made/scanned into a digital format. Typically I would use a PDF along with the zine design that I pre-formatted for this due to the clarity and easy access of PDF files. I avoid .png or .jpg because flattening my zine files tends to crush the text quality, by a LOT.
The Alpha copy doesn't have to just be the formatted version already. It can be individual panels, single pages, artwork or scanned pages, etc. That's also an alpha copy, but in its own way. The version I'm talking above is print-ready copy that is already prepared.

^ THIS counts as an alpha copy as well.
Now down below is an example of my own alpha copy in PDF format, featuring my DAVID SYLVIAN zine (I'll try to upload it on an archive soon, it will be completely free! Pls tell me in advance if you'd like to reproduce and distribute it irl since I dont want to get sued </3)

btw the tagline "be seen, make a zine" was taken from brattyxbre on YouTube. I would gladly recommend her for zine resources, discussions and zine-related topics, especially if you are a beginner!
BETA MASTER COPY (i.e.. PRINTED TEMPLATE)

Your Beta copy is a version of your zine that is printed on paper with the proper formatting for folding/cutting already. The only difference with this version and omega copy is, well, you DON'T fold or cut this copy.
The primary purpose of a B-Copy is to check:
print quality (text visibility, color vibrance, ink bleeding, etc.)
graphic size and an overview of your zine's general physical appearance.
And the other, marginally vital role of your B-Copy is to serve as:
the physical print that you can use for XEROX (photocopying) or other copying services and tools
scannable output that you can scan/copy for distribution, especially if the person who wants your zine would like to assemble it themselves, if you do not have a final version of your zine on hand to share, or you yourself do not have your A-Copy for reproduction.
A printed copy that you can catalogue or archive, especially if you are the sort of person who retires zines, or are just deeply sentimental (like me, lol!).
Down below is the B-Copy of my example zine. Ignore the fact that this is literally my omega copy that I just dismantled because I don't have my Beta in hand lol. But approximately this is how it looks like.

I personally store B-copies (alongside O-copies) inside a dedicated clearbook or binder to safeguard against weathering or chemical ink deterioration, alongside some information and stuff about the zine itself. This is useful especially if you want to showcase zines and zine content to others, apart from safekeeping purposes.
I might make another longform infodump about digital and physical zine storage and archiving processes (because as an aspiring librarian I feel it is my duty to rant about that) but that will be for another time.
OMEGA MASTER COPY (i.e., FINAL EXAMPLE PRINT)

Okay this is kind-of self explanatory, but I will elaborate regardless.
If you are the sort of person who handcrafts zines (aka make, draw, write or assemble them traditionally) you likely know what the O-Copy is, because your original finished zine is what I am referring to as the Omega copy. That is, the ACTUAL "Master Copy" itself.
Omega Master Copy is what most zinesters and zine creators refer to as just the master copy. But seeing from this post, you KNOW I had to make it fancier (read: unnecessarily complicated)
The Omega copy serves as your first official print, and you can use this version to store or show around. The only difference is, if you end up using my organizing format (good luck!), you'll end up using the O-Copy more as a finished product display to show how it looks when finished as an assembled copy, and the B-Copy as the actual thing you use to reproduce or duplicate your zines for distribution.
Here is the example of my O-copy for my example zine. (again you will be able to access this through an archive soon, maybe I will announce it later on or just post about where I store them digitally.)

I used the software development jargon ALPHA, BETA & OMEGA because it kind of fits(?) lol. I am not a coding aficionado but I know loosely enough to utilize the words. But also, live laugh omegaverse. hopefully this helps(?) but also if you reached to this point, hi. I'm glad you indulged in my little rant. EDIT: here's the Internet Archive Link for the specific zine featured in this post! Have fun! Communicate, create, zineovate! Until next time.
#zines#fanzine#zine#zine preview#art zine#zine making#zinester#mini zine#digital archiving#master copy#zineovator#self publishing#david sylvian#japan band
28 notes
·
View notes
Text
UNIT 9: Where in the World?
This unit involved working in new applications: Autodesk Maya and Unreal Engine. We were expected to complete animations for a game demo as well as include it in the game engine.
UNDERSTANDING MAYA: Learning through test animations To begin with, when I first learnt Maya we had created some test animations using the Williams Walk/Run cycles (shown below, right click to loop videos)
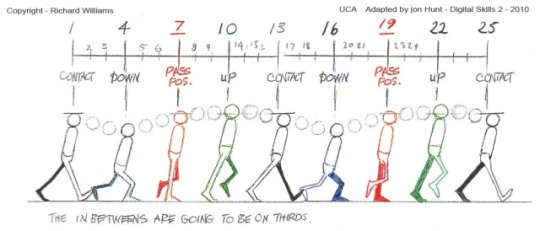

youtube
SECTION 1: Animating Files So, for this project we were given a model to create animations with, named AZRI. There was also an option to change the model, however I chose not to use a different model as I was used to the controls in this rig.
Most of these animations begin by compositing the key frames then using curves to refine them. Other frames could be added later for better flow and natural movement, but to begin with less was more: you could be more flexible with the movements until more keys were added.
Firstly, I made an attack swing. This would be the first attack we would use by default for the character. She steps forward, and lunges before going into neutral position. I could have had her step back on a delay instead of stepping back right after the swing is done. In addition to our attack swing we also had made an idle, which was basically a basic standing animation which had subtle movements which was meant to emulate natural breathing to make the character look alive.
Next, we had to make a double attack swing, however I did not include it in my game as I had included the special instead, which I had started outside of contact lesson times. It had used the single swing as the base, whereas the double swing did not.
My special attack swing involved some personal re-timing and math which I had noted myself. I had also used a reference of a friend for the swing forward attack to make it more believable.


Afterwards, I had made a walk and run cycle, which would later combine together in unreal with the idle to allow the character to move. I had improved on my run cycle to make it look less stiff through annotations by my tutor through SyncSketch.




What was also fully animated was a death animation, which featured the character falling into a comical pose emulating the Peter Griffin death stance.

Below is a link to all of the animations in .gif format as Tumblr does not allow me to import the animations because they're too big.
SECTION 2: Importing Animations and Coding in Unreal Engine This was the most fiddly as it involved node based coding. While most of the coding was provided for us already, we had to export our Maya files into FBX files. Due to some difficulties exporting, we had to export through Time Editor and process the animation through Game Exporter so that the animations would work in Unreal. Despite this, the transition into unreal was not difficult as much of the animations were turned into animation montages such as the attack, special and faint so that they can be triggered for certain events. These montages were then slotted into the pre-existing code so it could work.

On the other hand there was a blend space used for the movement to work, so that the character could move from idle, to running or walking depending on speed. However, since the engine would default to running, we had to add a toggle for the run to work. The button was shift, and holding shift enabled the user to run. We would also add sample smoothing so the transition between states was cleaner.
youtube




REDOING & ERRORS IN CODE AND SCRAPPED WORKS There were issues with rendering, as using Export All in Autodesk Maya did not always work. The solution was to use Time Editor to select everything then export using Game Editor. This is why in the final file some files have duplicates, experimental animations aside. As afformentioned, I had scrapped some animations, such as the double swing and the animation where the character got hit due to difficulty getting the animation right. The hit animation was something I was unsure to do and I did not have any clear reference for, so it would have looked slightly incorrect.
FINAL EDIT
youtube
Reflection Overall, compared to unit 8 most of what I did went smoothly, however I do think I could have had more care animating the frames and storyboarding the frames a LOT better as well as understanding how the framings work to make the steps in my animations work a lot more realistically. However I do think that Maya tools, especially the Graph Editor helped my animations look much more believable and real. If I were to do this project again I would definitely try to use more varied references. I would also fix the grip on the sword and if I wanted to time my work more accurately, then storyboard the animations withappropriate timings. I would have used an external application like Procreate which could hold frames instead to make the process quicker. I could have definitely streamlined my workflow for better peace of mind.
LINKS:
Company Research: COMPANY_RESEARCH_CHRISTINERADAZA.docx
OneDrive: UNIT_9_COMPLETE Game Zip: EXAMPLE_GAME-FINAL-ChristineRadaza.zip
0 notes
Text
Top Mistakes Beginners Make in Flutter (and How to Avoid Them)

Flutter is a powerful toolkit for creating apps on multiple platforms using a single codebase. However, beginners often face challenges as they get started. Common issues include misunderstanding widget structure, misusing stateful and stateless widgets, and ignoring proper state management. These mistakes can lead to messy code, poor performance, and difficult debugging. Recognizing these errors early helps developers write cleaner, more efficient apps and prevents long-term complications. With a focus on best practices, beginners can avoid frustration and quickly build functional, responsive interfaces. Learning from these early mistakes is a key step in mastering Flutter development.
1. Ignoring the Widget Tree Structure
Mistake: Many beginners start building UI without understanding the widget hierarchy. This leads to messy, hard-to-maintain code.
Solution: Learn the widget tree concept early. Break down your UI into smaller widgets. Use Column, Row, and Container wisely, and always aim for clean and readable structure.
2. Misusing Stateful and Stateless Widgets
Mistake: Using a StatefulWidget where a StatelessWidget would do, or vice versa, often results in unnecessary complexity or performance issues.
Solution: If your widget doesn't need to rebuild when something changes, keep it stateless. Only use stateful widgets when dynamic data is involved
3. Poor State Management
Mistake: Relying on setState() for everything or avoiding state management altogether can make apps buggy and difficult to scale.
Solution: Explore popular state management solutions like Provider, River pod, or Bloc. Pick one that fits your app’s complexity and stick to best practices.
4. Not Using Widgets Reuseably
Mistake: Copying and pasting code instead of creating reusable components can lead to code duplication and bloat.
Solution: Turn repetitive UI patterns into custom widgets. This makes your code modular, testable, and easier to maintain
5. Overlooking Performance Optimization
Mistake: Beginners often ignore performance until the app becomes slow or laggy, especially when building large UIs.
Solution: Use the Flutter DevTools to monitor performance. Avoid unnecessary rebuilds with tools like const constructors and shouldRebuild logic in custom widgets.
6. Forgetting to Handle Null Values
Mistake: Null safety in Dart is strict, and ignoring it leads to runtime errors that crash your app.
Solution: Always check for null values. Use the ?, !, and late keywords responsibly and understand what they mean in context.
7. Lack of Testing
Mistake: Skipping tests may not hurt early, but it creates big issues as the codebase grows.
Solution: Write unit tests, widget tests, and integration tests regularly. Flutter makes testing easier with built-in support-use it from day one.
8. Not Adapting for Different Screen Sizes
Mistake: Hardcoding dimensions results in layouts that break on different devices.
Solution: Use responsive design principles. Widgets like Expanded, Flexible, and MediaQuery help you build adaptable UIs for various screen sizes
9. Overcomplicating Navigation
Mistake: Beginners often over-engineer navigation with deeply nested routes or inconsistent logic.
Solution: Start simple with Flutter's built-in Navigator. When your app grows, consider using go_router or auto_route for better route management
10. Not Keeping Code Organized
Mistake: Putting all code into main. dart or a few large files makes your project hard to manage.
Solution: Organize code into folders like screens, widgets, models, and services. Follow clean architecture as your project scales.
Learning Flutter is an exciting journey, but being aware of these common mistakes can help you grow faster and code better. Focus on writing clean, reusable code, and don’t hesitate to learn from the vast Flutter community
0 notes
Text
Mastering Terraform IAC Development: Your Path to Efficient Infrastructure Automation 🚀

If you’ve been dipping your toes into the DevOps pool, chances are you’ve heard whispers—maybe even shouts—about Infrastructure as Code (IaC). Among the many tools out there, Terraform has emerged as a favorite. Why? Because it makes infrastructure automation feel less like rocket science and more like a well-organized checklist.
In this blog, we’re going deep into the world of Terraform IAC Development, unpacking everything from what it is to why it matters—and how you can become confident using it, even if you’re just starting out.
And the best part? We’ll show you exactly where to begin your learning journey. (Hint: It’s right here—this Terraform IAC Development course could be your launchpad.)
What is Terraform, and Why Is It So Popular?
Let’s break it down simply.
Terraform is an open-source tool developed by HashiCorp that allows you to define and provision infrastructure using a high-level configuration language called HCL (HashiCorp Configuration Language). Think of it as a blueprint for your cloud resources.
Instead of manually clicking around dashboards or writing endless scripts, you write code that defines what you want your infrastructure to look like. Then Terraform builds it for you. It’s fast, reliable, and most importantly, repeatable.
What Makes Terraform Stand Out?
Multi-Cloud Support: It works with AWS, Azure, GCP, Kubernetes, and even on-premise solutions.
Declarative Syntax: You declare what you want, and Terraform figures out how to get there.
State Management: Terraform keeps track of what’s been deployed, making updates clean and precise.
Modular Approach: Reusable modules mean less repetitive code and more consistent deployments.
Real-Life Problems Terraform Solves
Still wondering what makes Terraform so essential? Here are a few scenarios:
You're working with a team and need identical dev, test, and production environments. Manually setting that up can lead to errors. With Terraform, it's as easy as duplicating a few lines of code.
You want to migrate your workloads between cloud providers. Terraform’s provider ecosystem makes this not just possible—but surprisingly smooth.
You need to spin up infrastructure automatically when new code is deployed. Terraform works beautifully with CI/CD tools like Jenkins, GitHub Actions, and GitLab CI.
Bottom line: Terraform reduces human error, increases efficiency, and gives teams a single source of truth for infrastructure.
The Building Blocks of Terraform IAC Development
Before you dive in, let’s understand the key components of Terraform IAC Development:
1. Providers
These are plugins that allow Terraform to communicate with different cloud platforms. AWS, Azure, GCP, and even third-party tools like GitHub or Datadog have Terraform providers.
2. Resources
These define what you're provisioning—like an EC2 instance, a database, or a DNS record.
3. Modules
Modules group your resources and make your code reusable and cleaner. Think of them like functions in programming.
4. Variables
Want flexibility? Variables allow you to change configurations without editing your core code.
5. State Files
This is Terraform’s memory. It keeps track of the current infrastructure so Terraform knows what needs to change during an update.
How to Get Started with Terraform IAC Development
You don’t need a PhD in Cloud Engineering to get started with Terraform. In fact, all you need is:
A basic understanding of how cloud platforms work (AWS, Azure, etc.)
A terminal (Mac, Linux, or even Windows with WSL)
A code editor (VS Code is a great choice)
And a clear learning path
We recommend starting with this hands-on, beginner-friendly course on Terraform IAC Development. It’s packed with real-world examples, clear explanations, and exercises that build muscle memory.
Top Benefits of Learning Terraform Today
✅ High Demand in the Job Market
DevOps engineers with Terraform experience are incredibly valuable. Companies are hungry for professionals who can deploy, manage, and scale infrastructure the right way.
✅ Automation = Efficiency
Imagine deploying an entire cloud environment with one command. That’s the power you get with Terraform.
✅ Open-Source Community Support
With thousands of contributors and resources, you’re never alone on your learning journey.
✅ Works Across Environments
Whether you’re a startup running on a single AWS region or a Fortune 500 with multi-cloud needs, Terraform scales with you.
Terraform in Action: Common Use Cases
Still not convinced? Let’s look at some real-world uses of Terraform:
🔹 Spinning Up Cloud Infrastructure for Dev/Test
Use Terraform to quickly set up a dev environment that mirrors production. Developers test in real conditions, bugs get caught early, and everyone’s happier.
🔹 Infrastructure Version Control
You wouldn’t deploy app code without Git. Why treat infrastructure any differently? With Terraform, your infra lives in code, can be peer-reviewed, and is version-controlled.
🔹 Disaster Recovery and Backups
By having your entire infrastructure as code, disaster recovery becomes as simple as redeploying from a repository.
🔹 Multi-Environment Consistency
Terraform ensures that dev, staging, and production environments are consistent—no more “it works on my machine” issues.
Pro Tips for Terraform IAC Success
Here are some insider tips from experienced Terraform users:
Use Modules Early: It makes your code scalable and readable.
Keep State Files Secure: Use remote backends like AWS S3 with state locking.
Integrate with CI/CD Pipelines: Automate everything—from provisioning to destruction.
Document Your Code: Use comments and naming conventions for clarity.
Lint and Validate: Tools like tflint and terraform validate keep your code clean.
Who Should Learn Terraform?
You might be thinking, “Is Terraform right for me?”
Here’s a quick checklist:
You're a DevOps engineer wanting to automate infrastructure.
You're a developer building cloud-native apps.
You're a sysadmin managing cloud or on-premise servers.
You're an aspiring cloud architect looking to understand modern infra tools.
If you nodded at any of the above, then learning Terraform is a smart career move.
What to Expect from a Great Terraform Course
Not all Terraform tutorials are created equal. A truly valuable course should:
Cover real-world scenarios, not just theory.
Offer hands-on labs and assignments.
Explain concepts in plain English, without jargon.
Be updated regularly with the latest Terraform versions.
Include lifetime access, because learning never stops.
Looking for all that in one place? Check out this complete course on Terraform IAC Development. It’s designed for beginners and pros alike.
Terraform vs Other IaC Tools
You might be wondering how Terraform stacks up against other tools like AWS CloudFormation, Ansible, or Pulumi.
Here’s a quick comparison: FeatureTerraformCloudFormationAnsiblePulumiMulti-Cloud✅ Yes❌ AWS-only✅ Yes✅ YesDeclarative Syntax✅ Yes✅ Yes❌ Imperative✅ Yes (but with code)Open Source✅ Yes❌ No✅ Yes✅ YesState Management✅ Yes✅ Yes❌ No✅ YesLanguageHCLJSON/YAMLYAMLPython/Go/TS
Terraform in the Real World: Career Paths and Projects
Let’s get practical. Once you know Terraform, what can you do?
🔧 Automate Cloud Deployments
Work in teams building and scaling AWS, Azure, or GCP infrastructure with a few lines of code.
🧰 Build CI/CD Pipelines
Use Terraform to provision resources automatically when code is pushed.
🔍 Improve Infrastructure Security
With clear, version-controlled code, vulnerabilities are easier to detect.
💼 Land DevOps Jobs
From startups to enterprises, employers love candidates who know how to manage infra with code.
Final Thoughts: The Future is Written in Code
Cloud computing isn’t slowing down. Neither is the need for automation. Terraform IAC Development is a skill that helps you stand out in the competitive world of DevOps, cloud, and infrastructure management.
You don’t need to be a cloud guru to get started. All it takes is the right guide, some curiosity, and a bit of practice. This Terraform IAC Development course is the perfect first step—and you can start learning today.
0 notes
Text
Top AI Trends in Medical Record Review for 2025 and Beyond
When every minute counts and the volume of documentation keeps growing, professionals handling medical records often face a familiar bottleneck—navigating through massive, redundant files to pinpoint crucial medical data. Whether for independent medical exams (IMEs), peer reviews, or litigation support, delays, and inaccuracies in reviewing records can disrupt decision-making, increase overhead, and pose compliance risks.
That's where AI is stepping in—not as a future solution but as a game changer.
From Data Overload to Data Precision
Manual review processes often fall short when records include thousands of pages with duplicated reports, handwritten notes, and scattered information. AI-powered medical records review services now bring precision, speed, and structure to this chaos.
AI/ML model scans entire sets of medical documents, learns from structured and unstructured data, and identifies critical data points—physician notes, prescriptions, lab values, diagnosis codes, imaging results, and provider details. The system then indexes and sorts records according to the date of injury and treatment visits, ensuring clear chronological visibility.
Once organized, the engine produces concise summaries tailored for quick decision-making—ideal for deposition summaries, peer reviews, and IME/QME reports.
Key AI Trends Reshaping 2025 and Beyond
1. Contextual AI Summarization
Summaries are no longer just text extractions. AI models are becoming context-aware, producing focused narratives that eliminate repetition and highlight medically significant events—exactly what reviewers need when building a case or evaluating medical necessity.
2. Intelligent Indexing & Chronology Sorting
Chronological sorting is moving beyond simple date alignment. AI models now associate events with the treatment cycle, grouping diagnostics, prescriptions, and physician notes by the injury timeline—offering a cleaner, more logical flow of information.
3. Deduplication & Version Control
Duplicate documents create confusion and waste time. Advanced AI can now detect and remove near-identical reports, earlier versions, and misfiled documents while preserving audit trails. This alone reduces review fatigue and administrative overhead.
4. Custom Output Formats
Different reviewers prefer different formats. AI-driven platforms offer customizable outputs—hyperlinked reports, annotated PDFs, or clean deposition summaries—ready for court proceedings or clinical assessments.
Why This Matters Now
The pressure to process records faster, more accurately, and at scale is growing. Workers' comp cases and utilization reviews depend on fast and clear insights. AI-powered medical records review service providers bring the tools to meet that demand—not just for efficiency but also for risk mitigation and quality outcomes.
Why Partner with an AI-Driven Medical Records Review Provider?
A reliable partner can bring scalable infrastructure, domain-trained AI models, and compliance-ready outputs. That's not just an operational upgrade—it's a strategic advantage. As the demand for faster, more intelligent medical records review services grows, those who invest in AI-driven solutions will lead the next phase of review excellence.
0 notes
Text
How Claim Verification Automation and AI Reduce Denials and Delays?

How Claim Verification Automation and AI Reduce Denials and Delays?
Introduction
Managing insurance claims manually leads to inefficiencies, errors, and payment delays. Incorrect details and coding mistakes cause denials, impacting revenue and increasing administrative burdens. Claim verification automation and AI streamline processes, proactively detect errors, and ensure compliance, reducing denials and accelerating reimbursements. This article explores how automation and AI enhance efficiency, eliminate errors, and optimize revenue cycle managementfor healthcare providers.
Understanding Claim Verification
Claim verification is essential in medical billing to ensure accuracy, completeness, and compliance before submission. Healthcare providers must confirm patient details, insurance eligibility, service codes, and supporting documents to prevent errors. Mistakes can lead to denials, requiring rework and delaying payments. Automating verification with AI reduces manual errors, detects inconsistencies in real time, and enhances financial stability. By streamlining the process, healthcare facilities can improve efficiency, minimize claim rejections, and accelerate reimbursements.
Common Causes of Claim Denials
Understanding the reasons behind claim denials helps providers implement effective solutions. The most frequent causes include:
Incorrect Patient Information: Even a minor typo in a patient’s name, date of birth, or insurance details can lead to a denial.
Lack of Medical Necessity: If payers find insufficient justification for a procedure, they may reject the claim.
Coding Errors: Inaccurate CPT, ICD-10, or HCPCS codes are common reasons for claim rejections.
Duplicate Claims: Submitting the same claim multiple times due to system errors or miscommunication can cause unnecessary delays.
Missed Deadlines: Insurance companies impose strict timelines for claim submission. Late filings often result in automatic denials.
The Role of Automation in Claim Verification
Automation is revolutionizing claim verification by eliminating manual intervention and ensuring accuracy before submission. Automated tools perform critical functions such as:
Extracting patient demographics and insurance details from electronic health records (EHRs)
Validating information against payer requirements
Identifying missing or incorrect data instantly
Reducing administrative workload and human error
These features help providers submit cleaner claims, increasing the chances of first-pass approval and minimizing the need for resubmissions.
How AI Enhances Claim Verification
AI takes automation a step further by integrating machine learning algorithms that analyze vast amounts of claim data. By recognizing patterns and predicting errors, AI-driven systems can proactively correct mistakes before submission. Here’s how AI contributes to the claim verification process:
Real-Time Error Detection: AI scans claims for missing documentation, incorrect codes, and potential compliance issues.
Predictive Analytics: Machine learning models analyze past claim denials to identify patterns and prevent future errors.
Automated Decision-Making: AI-powered systems determine claim eligibility based on payer policies, reducing the likelihood of denials.
By continuously learning and adapting to changing regulations, AI ensures that claims meet the latest industry standards and payer-specific guidelines.
Reducing Errors with AI and Automation
Human errors in claim submissions often lead to denials, requiring additional time and effort to resolve. AI and automation address these issues by:
Eliminating Manual Data Entry: Automated systems extract data directly from medical records, reducing the risk of input errors.
Ensuring Accurate Coding: AI-driven coding assistants verify CPT and ICD-10 codes to prevent incorrect billing.
Flagging Missing Documentation:Automated checks ensure that all required attachments, such as physician notes and prior authorizations, are included.
With AI and automation, providers can achieve higher claim acceptance rates and reduce revenue losses associated with rework and resubmissions.
Faster Claim Processing and Approval
Traditional claim processing can take days or even weeks due to manual reviews and back-and-forth communication with insurers. AI-driven automation accelerates approvals by:
Auto-Filling Claim Details: Reducing manual input speeds up the submission process.
Cross-Referencing with Insurance Databases: Ensuring real-time eligibility verification before claim submission.
Instantly Flagging Discrepancies:Enabling quick corrections and reducing processing delays.
As a result, healthcare providers experience faster reimbursements, improved cash flow, and reduced administrative burdens.
Cost Savings for Healthcare Providers
By adopting AI and automation, medical practices can significantly cut operational costs. Automated claim verification reduces the need for extensive manual review teams, lowering labor expenses. Additionally, fewer claim denials mean less time spent on appeals and corrections, allowing billing staff to focus on higher-value tasks. The overall efficiency gains contribute to increased revenue cycle optimization.
Enhancing Compliance and Accuracy
Medical billing regulations change frequently, making compliance a challenge for healthcare providers. AI-powered claim verification systems stay updated with the latest industry standards, ensuring that claims adhere to:
HIPAA guidelines for data security
Medicare and Medicaid policies
Payer-specific billing rules
By maintaining compliance, providers avoid penalties, audits, and revenue loss due to claim rejections.
Real-World Success Stories of AI in Claim Verification
Many healthcare organizations have successfully implemented AI-driven claim verification solutions. For example:
Hospitals using AI-powered coding assistants have reported a 30% decrease in claim denials.
Medical practices utilizing automated eligibility checks have seen faster reimbursement cycles and improved cash flow.
These success stories highlight the tangible benefits of AI and automation in medical billing.
The Future of AI in Healthcare Claims Processing
As AI technology evolves, its role in claim verification will continue to expand. Future advancements may include:
Advanced Predictive Analytics: AI will detect potential denials before claims are even submitted.
Seamless Integration with EHRs:Enhanced interoperability will streamline data exchange between healthcare systems and insurers.
Real-Time Claim Tracking:Providers will have full visibility into the status of claims, improving transparency and efficiency.
Conclusion
Claim verification automation and AI are revolutionizing the healthcare industry by minimizing denials, reducing processing delays, and improving revenue cycle management. By leveraging these advanced technologies, medical providers can streamline billing operations, enhance compliance, and focus more on delivering quality patient care. As AI continues to evolve, embracing these tools will be essential for staying competitive in an increasingly complex healthcare landscape.
Outsourcing medical coding and billing services providers like Info Hub Consultancy Services offer expert solutions to optimize claim verification and revenue cycle management. Partnering with a trusted outsourcing provider ensures accuracy, compliance, and faster reimbursements, allowing healthcare providers to focus on patient care.
Contact Info Hub Consultancy Services today to streamline your billing operations and reduce claim denials.
#Outsource Medical Billing#Medical Billing Company#Best Outsource Medical Billing and coding Company#Top Outsource Medical Billing company#Offshore Medical Billing Services Providers In India#Outsource Medical Coding Companies India#Outsource Medical Billing Services Providers In India#Offshore Medical Coding Services Providers In India
0 notes
Text
JS2TS tool and TypeScript Best Practices: Writing Clean and Scalable Code
Introduction
Working with TypeScript, we have to write clean and scalable code; that is crucial for any development project. TypeScript provides a structure and type safety guarantee to JavaScript, which makes the code easier to maintain and debug. But type definitions across large projects are not easy to ensure consistency.
JS2TS tool makes this process much easier by automatically translating JSON data into hard TypeScript interface. The JS2TS tool allows developers to, instead of manual type definition, just define their types and generate structured and reusable type definitions automatically. But it not only saves time, it reduces the amount of rubbish code out in the open (bad code is spoken of by many as ‘the thing’). It produces cleaner, more maintainable, and more scalable code.
About JS2TS tool
The JS2TS tool is a very good tool to convert JSON data to very exact TypeScript interfaces. We know that JSON is extremely popular for APIs, databases, and configuring files; thus, in order to define it in a TypeScript format, this can become very time-consuming and prone to errors.
The JS2TS tool automates that by creating nicely formatted TypeScript interfaces in a couple of seconds. The JS2TS tool helps developers get rid of inconsistencies in type definitions, minimize human errors, and keep up coding standards in projects.
About TypeScript
TypeScript is a superset of JavaScript that will add reliability and scalability. Along with static typing, interfaces, and strict type checks they also introduce to us, which catch errors early and write more predictable code.
Type definitions enforce a structured format for functions, variables, and objects in order to ensure that they follow. Both patterns and it allow code bases to scale well in large projects with many developers, better debugging, and maintainability.
Importance of Clean and Scalable TypeScript Code
The clean and scalable code is necessary for developing efficient, maintainable, and error-free applications. Maintaining well-organized type definitions is very important in a TypeScript codebase so that the code can remain readable and changeable as the project grows.
Automatically defining type structures on teams reduces the chances of introducing bugs due to inconsistency, the amount of redundant code, and confusion during collaboration. Similarly, they improve code reusability, make the program more performant, and are easier to debug.
Developers, through the best practices and the aid of automated tools like the JS2TS, ensure that their TypeScript code remains consistent, sustainable, and due to standards of industry.
How does the JS2TS tool ensure consistency in type definitions?
Maintaining the consistent type definitions across the whole project is considered one of the biggest challenges in TypeScript development. Types defined by hand require consistent efforts, redundant interfaces, and bugs that are harder to understand.
The JS2TS tool solves these problems by converting this automatically, so all the type definitions are in standardized format. In other words, each developer on the team has the same, well-structured interfaces to work with and thus better code organization, fewer conflicts, and better collaboration.
Using the JS2TS tool, teams enforce one source of truth for data structures, less duplication, and also a more reliable codebase.
Best Practices for using JS2TS tool in Large Projects
It is important to keep modular and reusable type definitions for large-scale applications. The JS2TS tool enables developers to do this by creating accurate and reusable interfaces that can be stored in separate files and used across the whole project.
In addition, developers can generate type definitions with the JS2TS tool from API responses to minimize differences in data structure between frontend and backend teams. It helps in collaboration, reduces the miscommunication, and increases the speed of the development.
Also Read: How to Convert JSON to TypeScript Made Easy?
One of the best practices is to include integration of the JS2TS tool into the development workflow. The JS2TS tool allows developers to simply define new interfaces upon changing an API, allowing the code to auto-update without disintegrating into production delivery errors.
How does the JS2TS tool align with TypeScript best practices?
Type safety, reusability, and maintainability are emphasized as the best practices of TypeScript. The JS2TS tool can help the developer follow these principles by automating the creation of the structured, reusable, and precise type definition.
The JS2TS tool is creating interfaces from given JSON data, thus reducing the chance of missing or wrong type definitions, which assures that TypeScript code is strict about type checkups. It reduces the number of runtime errors, helps save the code from being broken, and makes long-term maintainability better.
Also Read: Convert Object to JSON in a Snap
As with most of the services mentioned on this page, integrating the JS2TS tool into a workflow helps enable developers to manage types better, ensure the correct coding standards and create TypeScript code that will easily scale.
Conclusion
Writing clean, structured, and scallable TypeScript code is a JS2TS tool. It kills manual error, increases consistency, and makes sure the best coding practices are implemented by automating type definition generation.
The JS2TS tool makes its life much easier for developers and teams working on TypeScript projects and more reliably maintains and defines types. JS2TS tool can be used when building small applications or a large system and is the key to writing better TypeScript code with minimum effort.
JS2TS offers you JS2TS tool, your purely effort solution today to type in TypeScript type definitions!
0 notes
Text
Version 605
youtube
windows
zip
exe
macOS
app
linux
tar.zst
I had a great week working on a bunch of small issues and cleanup. There's also a user contribution that adds ratings to thumbnails!
full changelog
highlights
First, if you would like to try showing ratings on your thumbnails, each rating service panel in services->manage services now has a couple new checkboxes to show the ratings, either only when the file has a rating, or all the time. Unfortunately, the ratings can sometimes get washed out by the text banner or thumbnail image behind them, and while I tried to fix it with a very very subtle backing shadow, I think it needs a bit more work to look 'nice' (the whole ratings system does). Let me know what you think!
I gave the advanced deletion dialog's 'deletion reason' list a full pass (the code behind the scenes was super ugly), and it is now more stable and highlights and sets 'existing deletion reason' and, optionally, 'last used reason' much more reliably.
If you use e621 a lot, there's a new non-default downloader that grabs the (new?) 'contributor' namespace, which tracks VAs and modellers different to the primary artist. There's also an update to the e621 style, thanks to a user. Check the changelog for more details.
In the duplicates filter, the two files are renamed from 'A' and 'B' to 'File One' and 'File Two'. It is a silly change, but I'm firming up some nomenclature behind the scenes as I work on duplicates auto-resolution. The filter's hover window now also shows the score difference between the two files as a number--let's see if it is useful.
I fixed a ton of jank layout this week. Many panels will now expand more sensibly or are simply laid out cleaner. I'm may have typo'd something or didn't realise some knock-on effect somewhere that I didn't test, so if you see any text in an out-of-the-way dialog suddenly out of alignment somewhere, let me know!
next week
I finished another duplicates auto-resolution tab this week. I've now got two difficult things and a bunch of tying-together to do and we'll be ready for an IRL test. I'm feeling great about it and I want to keep pushing. Otherwise more small work and cleanup like this.
0 notes
Text
Mastering Excel Power Query: With GVT Academy’s Advanced Excel Course

In today’s data-driven world, efficiency in data handling and analysis is vital for any professional. Businesses, students, and data enthusiasts alike benefit from tools that simplify data processes and make it easier to extract insights. Microsoft Excel, a staple in data analysis, continues to innovate with powerful tools, one of the most transformative being Excel Power Query. With Power Query, users can clean, transform, and load data seamlessly, saving hours of manual work and reducing errors. GVT Academy’s Advanced Excel Course is designed to empower students and professionals with the skills needed to harness the full potential of this tool. Here’s how this course can elevate your data management skills and why it’s an investment in your career.
What is an Excel Power Query?
Excel Power Query is a powerful tool within Excel that allows users to connect to various data sources, then organize, transform, and combine data seamlessly. It’s integrated into Excel as the Get & Transform feature, making it accessible for everyone from beginners to advanced users. Power Query allows you to automate data cleaning, removing redundancies and errors while keeping your data organized.
With Power Query, you don’t need to be an expert in complex functions or coding. This tool uses a simple, user-friendly interface to guide users through every step of the data transformation process. Power Query’s flexibility in connecting to numerous data sources, including databases, web pages, and CSV files, is a game-changer for those who work with large datasets or regularly update data from external sources.
Why Mastering Excel Power Query is Essential
Mastering Power Query offers several advantages:
Streamlined Data Preparation: Transforming raw data into a usable format can be one of the most time-consuming tasks in Excel. Power Query’s automated transformation capabilities make data preparation effortless.
Improved Accuracy and Consistency: Power Query reduces human error, which is often introduced during manual data handling, ensuring data consistency across reports.
Enhanced Data Analysis: With cleaner, well-organized data, users can analyze trends, patterns, and outliers with ease, unlocking insights that drive better decision-making.
Time Savings: Automating repetitive tasks like data cleaning, merging, and updating saves significant time, allowing users to focus on deeper analysis rather than manual data wrangling.
Key Skills You Will Learn in GVT Academy’s Mastering Advanced Excel Course
GVT Academy’s course is meticulously crafted to provide a comprehensive understanding of Power Query’s features and how to use them effectively. Here’s a breakdown of what you’ll learn:
1. Data Connection and Integration
Learn to connect Excel to multiple data sources, from databases to cloud services, and pull in data effortlessly.
Understand how to keep data refreshed and automatically updated from these sources, eliminating the need for manual imports.
2. Data Transformation Techniques
Discover techniques to clean, filter, and format data quickly using Power Query’s transformation tools.
Handle issues like missing data, duplicate values, and inconsistent formats, resulting in a clean, usable dataset.
3. Merging and Appending Data
Gain proficiency in combining multiple tables and data sets, which is essential for complex analyses.
Understand when to use merge versus append operations for effective data management.
4. Data Shaping and Modeling
Shape data into the right format for analysis, including pivoting, unpivoting, and grouping data.
Master the art of creating data models that allow for more advanced analyses, connecting various tables to derive insights.
5. Automation of Data Processing
Automate recurring data processing tasks, so reports and analyses can be updated with a single click.
Understand how to document your Power Query steps for easy replication and auditing.
6. Advanced Data Analysis
Learn advanced techniques like conditional columns, parameterized queries, and using M code to customize data transformations.
Explore methods to integrate Power Query with other Excel tools like Power Pivot for deeper insights.
Benefits of Taking the Advanced Excel Course at GVT Academy
Choosing GVT Academy’s Advanced Excel course means you’re investing in quality education and career-enhancing skills. Here’s what sets this course apart:
Hands-On Training: At GVT Academy, our course is designed to provide real-world applications, allowing you to work on sample datasets and case studies that mirror the challenges faced by businesses today.
Expert Guidance: The course is led by seasoned data analysts and Excel experts who bring a wealth of experience, ensuring that you gain valuable insights and practical knowledge.
Flexible Learning Options: Our course is available in both online and offline formats, making it accessible regardless of your schedule or location.
Certification and Career Support: Upon completing the course, you’ll receive a certification from GVT Academy that enhances your resume. Additionally, we offer career support to help you apply these skills in your current role or pursue new career opportunities.
How This Course Supports Your Career Growth
As data literacy becomes a highly sought-after skill across industries, Power Query expertise positions you as a valuable asset in your organization. This course:
Boosts Your Resume: Excel Power Query skills are in demand, and having this certification from GVT Academy makes your resume stand out.
Increases Your Efficiency: Employers value employees who can optimize workflows and make data-driven decisions. Power Query allows you to streamline your data processes and boost productivity.
Prepares You for Advanced Data Roles: Mastering Power Query can serve as a foundation for learning other data analysis tools, such as SQL, Power BI, or Python, which are essential for more advanced roles in data science.
Enroll in GVT Academy’s Power Query Course Today!
Mastering Excel Power Query is an investment in your career that pays dividends in saved time, increased accuracy, and improved data analysis capabilities. At GVT Academy, we’re committed to equipping you with practical, real-world skills that set you apart in the workplace.
Ready to become proficient in data transformation? Enroll in our Advanced Excel course today and start transforming and analyzing data with ease!
#gvt academy#advanced excel training institute in noida#excel training course#advanced excel training
0 notes
Text
Examining the Benefits of C# Implicit Usings
Have you thought about how using Implicit Usings can change the way you design C# applications? The laborious process of manually incorporating the identical using statements in many files is a common task for C# developers, which results in crowded code and more maintenance work. Implicit usings, introduced in .NET 6, allow the compiler to automatically include commonly used namespaces, greatly increasing coding efficiency. Further flexibility is provided by the option to design unique global usings that are exclusive to your projects.
The Problem with Duplicate Uses
Developers frequently discover that common namespaces—like System, System. Collections. Generic and System Linq—are declared many times in different files in numerous projects. This redundancy makes the code more difficult to comprehend and maintain in addition to making it more complex.
What could be the simplified approach?
Consider defining these common namespaces globally for your entire project in a dedicated file, like GlobalUsings.cs, to solve this problem. This methodology not only mitigates redundancy but also fosters a better structured code structure. The development process is made simpler by centralizing your using statements, which establish a single point of truth for namespace declarations.
Why adopt implicit using?
Improved Code Clarity: Your code gets clearer and cleaner when you remove unnecessary using statements. You and your team will find it simpler to explore and comprehend the codebase because of this simplification.
Simplified Maintenance: By consolidating your using statements into a single file, you can make additions and changes in one place. Error risk is greatly decreased by this centralized administration, which guarantees that changes are automatically reflected throughout your project.
Improved Collaboration: Because they can concentrate on functionality instead of being distracted by repeated pronouncements, team members may collaborate more successfully when there is consistency.
Increased Productivity: You'll be able to write business logic and implement features more intently and spend less time managing boilerplate code by optimizing your code and cutting out redundant parts.
Key Takeaways
One useful feature that can significantly improve the readability and maintainability of your C# code is implicit usings. By implementing this technique, you promote a more productive and cooperative development atmosphere in addition to streamlining your projects. Beyond only increasing individual productivity, the advantages also improve team dynamics and project success.
More Considerations:
Consider the following recommended techniques while implementing implicit usings:
Utilize IDE Features: A lot of integrated development environments (IDEs) provide resources for efficient usage management. To further improve your productivity, use these tools to automate the process of adding and removing namespaces as needed.
Analyze Namespace Utilization: Make sure the namespaces you use are still essential and relevant by regularly reviewing them. By doing this, needless imports that can cause confusion and clutter are avoided.
Stay updated: Since new features and advancements pertaining to usings and other language enhancements are always being introduced, stay up to current on developments in the .NET environment. Maintaining awareness enables you to take advantage of the most recent developments in your development procedures.
Embrace the power of implicit usings to improve your C# development processes right now! You can write code that is more streamlined, effective, and long-lasting by doing this. Making the switch to implicit usings not only makes code easier, but it also fosters a culture that values creativity and teamwork.
0 notes
Text
UI Crescendo
So now I gotta extend the UI to draw more than just buttons I suppose
My first thought is to do the obvious thing and have a UIElement base class, from which individual elements can derive. The problem with this is that we're hot-reloading the game from a .dll, so vtables have a tendency to get thrashed when we reload, so we'll jump into stale memory and try to execute malformed instructions (what we professionals call a "big yikes").
We're persisting UI elements because we've split the update and render steps, so we just need to clear the stale state on reload. So we'll add a callback that we can fire right before unloading the dll, and use that to clear all the stale elements

We also add an Allocator struct so that we can bundle malloc AND free and simplify that plumbing.
Then in the main (non-dylib) part,
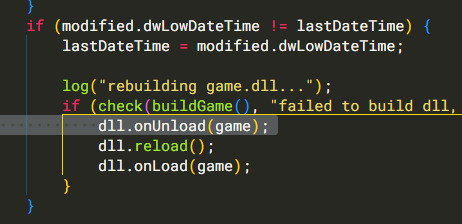
and when we unload the game, clear the UI elements
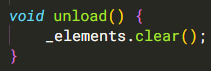
(a simpler thing to do would be to clear the buffered UI elements after rendering them so that we never persist them across frames regardless of whether we reload the dll. However we *do* persist interaction data (button state) from frame to frame, so it's pretty important that we not do that. This does mean we lose clicks in progress when the dll reloads, but that should never happen to non-devs (and is impractical to reproduce for devs, at that), so #NAB #wontfix)
Then I realize that we still have problems, because we need to store some kind of runtime type information (RTTI) so we know how to actually update the elements in question. So if we have to add an enum per derived class, store that in the base class, and make sure that stays in sync, that seems way messier than just using an ADT-like design in the first place. (Dr. Hindsight here: dynamic_cast would probably have worked just fine, I just didn't think about it until typing "RTTI" just now)
So uh what are ADTs? Well if you go full expanding brain memes and do pure-functional programming, you wind up in the land of Algebraic Data Types. Specifically Sum types, so called because the members of a type are the SUM of possibilities of its components. Which is to say a UIElement can be a Button OR a text Label. And another way to say sum/or is "union"

this is basically the mechanism behind how Haskell's sum types work, only with more footguns because we're dealing with the plumbing directly. Fortunately we're using these as essentially an implementation detail, so we control access to a very limited number of public interfaces, so what could possibly go wrong?
(I should probably split some of this stuff out of being all in one big game.cpp file, which would let me actually hide these implementation details, but we'll deal with that cleanup when it becomes more relevant)
back in the UI class, let's pull out the code that validates our element index, because we'll need to duplicate this logic for every type of thing

and now our button preamble looks like this,

that elem.kind jiggery-pokery is something we'll need to repeat at least once per element, which is annoying, but the cleanest way to reduce the repetition is with a macro, and frankly I'd rather not
Now then we just add a label method to add text elements,

and some helper methods to handle formatting numbers (todo: formatting)
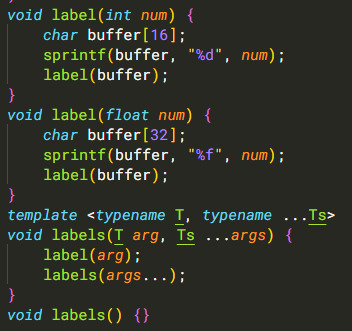
All of that leads us to this rather-svelte result for actually building a UI

which rendered in-engine, finally, nets us,

If you can't tell, I am very much of the "MIT approach" to software, where I will spend tremendous amounts of effort in the Implementation, in order to have a cleaner Interface. I did used to be a compiler engineer after all. This is probably related to why I have yet to ship a commercial product solo, isn't it.

anyhow, all that was a bunch of architectural gobbledygook. Mostly just figuring out how to partition the problem and what mechanisms to use in order to not explode within the confines of dll hot-reloading, while still scaling linearly with additional elements. In theory, adding different types of elements at this point should be straightforward, not requiring much additional infrastructure. (In theory, theory and practice are identical. In practice...)
Now, the thing that's cool about the imgui-style of UI architecture is that it lets you make compound custom widgets via simple composition of existing elements. Meaning that application logic doesn't need to deal with any of the complexity of the underlying system.
So the specific thing I wanted a UI for was to tweak the parameters of the texture generator. At some point I pulled out all the different constants I was using, so I could have them all collated in the same space

I don't have default values there, because I set the values in the onLoad callback, so they update whenever I change the code and rebuild

(and I do mean whenever I change the code; I have it watching game.cpp for changes and rebuilding in the main .exe, so that's automated too)
So that's *pretty good*, but it's still a two second compile every time I want to make a tweak to the parameters, along with being in a separate window from where the textures are actually displayed. It would be way smoother to get that down to near-instantaneous

yeah yeah you get the idea
so now I can create a custom widget for each parameter I want to change, consisting of a button each to increase and decrease the value, plus displaying the current value

this is just a normal function that takes parameters totally orthogonal to the UI, that does whatever arbitrary logic it wants, with no custom rendering logic or anything. (Ideally this would use a Slider element, and lo/hi would dictate the range of values, but that would be a new element type, and I'm sick of dealing with UI internals and just want to move on to doing other stuff for a bit)
so now we can remove the onload logic ("I fucking love deleting //todo:s" etc), set those values as defaults, and update our UI code:

which does Pretty Much What You'd Expect

reducing iteration time down ot the 50ms it takes to generate a new batch of 16 textures. amazing
note that we're setting min/max manually, and we could probably reduce repetition by factoring out the common case where we just +/- one with some minimum, this is Good Enough and sufficiently obvious that I'm fine with it
so of course I start playing around with it (noise size = 7, tex size = 16, noise scale = 1, mode = 3, tex repetitions = 8)

ok this one too (noise size 31, noise scale 4, tex size 1024, tex repetitions 1)

and mode 2, noise scale 9 (3 repeating bands of blue, red, green)

mode 3, noise scale 3, noise size 13, repetitions 16

so, the moral here I guess is that by making it more fun to mess around with, I'm more likely to explore the possibility space. Which was the whole point of investing in better tooling in the first place :)
0 notes
Text
What are the Source Code Checker's main responsibilities?
Source code is known as the backbone of software applications, and its quality is critical for ensuring the reliability, security, and maintainability of software. However, a Source Code Checker, also known as a Static Code Analysis tool, is a specialized software tool designed to analyze source code for potential issues and vulnerabilities to coding standards.
Additionally, this technology plays a crucial role in modern software development by helping developers identify as well as rectify problems early in the development process. This article explores the concept of Source Code Checkers, their significance, and how they contribute to improving software quality and security. Let's understand more about this topic.

What is a source code checker?
A source code checker is a software tool or program that examines the source code of computer programs to identify existing errors or issues, without the actual execution of the code. In other words, these tools are designed to analyze code at a static level, meaning they examine the code as it is written, without running or executing the program.
Source code checkers are commonly used in software development and quality assurance processes to improve code quality, maintainability, and security. In all a Source Code Checker is an automated tool that scans source code files to identify a wide range of issues, including:
Bugs and Logic Errors:
It helps in detecting code that may lead to runtime errors, crashes, or unexpected behavior.
Security Vulnerabilities:
Assists in identifying vulnerabilities such as SQL injection, cross-site scripting (XSS), and buffer overflows.
Code Complexity:
By analyzing code complexity metrics one can improve code readability and maintainability.
Code Duplication:
Identifying duplicated code can be a source of maintenance issues.
Performance Bottlenecks:
Source code detector helps in detecting code that may lead to suboptimal performance or resource leaks.
Key Functions and Purpose of a Source Code Checker
Until now you know what a source code checker is, let's have a look at a few key functions of the purpose of a source code checker:
Code Quality Improvement
These tools can enforce coding standards and best practices, helping developers write cleaner and more maintainable code. They can check for consistent naming conventions, indentation, and other coding style guidelines.
Error Detection
Source code checkers can identify various types of errors or issues in the code, such as syntax errors, logical errors, and coding style violations. They can flag issues that might lead to runtime errors or unexpected behavior when the code is executed.
Performance Optimization
Some source code checkers can analyze code for performance bottlenecks or inefficient coding patterns, helping developers optimize their code for better runtime performance.
Compliance checking
In industries like healthcare or finance, source code checkers can help ensure the code complies with relevant standards and regulations.
Security Analysis
Source code checkers can detect security vulnerabilities and weaknesses in the code, such as potential buffer overflows, SQL injection vulnerabilities, or insecure coding practices. Identifying these issues early can help prevent security breaches. To know more visit our website.
1 note
·
View note
Text
Duplicate file cleaner code

#DUPLICATE FILE CLEANER CODE UPDATE#
#DUPLICATE FILE CLEANER CODE SOFTWARE#
#DUPLICATE FILE CLEANER CODE CODE#
#DUPLICATE FILE CLEANER CODE CODE#
Linked Duplicate File Finder Plus Single License discounts code are official link from.100% satisfaction guaranteed, refundable, follow the Trisunsoft policy.100% working and be verified most recent Duplicate File Finder Plus Single License coupon discount code.
#DUPLICATE FILE CLEANER CODE UPDATE#
The highest discount worldwide for Duplicate File Finder Plus Single License, weekly update.What sets us apart from all the others discount site? Your private data is 100% safe, as ShareIT/2Checkout/Cleverbridge/Payproglobal complies with the latest online security standards. The whole ordering process is supported by ShareIT/2Checkout/Cleverbridge/Payproglobal, who handles all transactions details.
#DUPLICATE FILE CLEANER CODE SOFTWARE#
TriSun Software Limited will be happy to help you if there is any problem with your purchase.įor your convenience, TriSun Software Limited teamed up with ShareIT/2Checkout/Cleverbridge/Payproglobal to provide a secure and reliable platform for claiming Duplicate File Finder Plus Single License coupon code online. So, don't worry when buying Duplicate File Finder Plus Single License with our offering coupon code.ĭuplicate File Finder Plus Single License is backed by Trisunsoft's guarantee of quality customer service. ShareIT/2Checkout/Cleverbridge/Payproglobal support Credit/Debit Card, PayPal and 45+ other payment methods. ShareIT/2Checkout/Cleverbridge/Payproglobal are the authorized minor party payment processor of (TriSun Software Limited) products. This discounts code from Trisunsoft is issued by Trisunsoft. You can contact with this publisher at to get confirmation about this Duplicate File Finder Plus Single License discounts codes. So, this Duplicate File Finder Plus Single License coupon discount and linked-coupon are legit and conforming to the Trisunsoft rules. We, iVoicesoft are one of partner of Trisunsoft. Just only click on Quick link to use coupon to claim our offer of Duplicate File Finder Plus Single License promotions and save your money. We also show the best reductions on all Trisunsoft products, include Duplicate File Finder Plus Single License coupon code also, in comparing with others edition of Duplicate File Finder Plus Single License. We are collecting and offering to you the latest and formidable Duplicate File Finder Plus Single License discounts code with the highest discount amount. We try to make claming discount sounds as simple as possible, don't worry about your discount code. Why apply Duplicate File Finder Plus Single License discount coupon code from iVoicesoft? (Publisher's description, source:, TriSun Software Limited, Awesome offer code of Duplicate File Finder Plus Single License, tested & approved. The formidable National Singles Day discounts of Duplicate File Finder Plus Single License in 09/2022. Duplicate File Finder Plus Single License Coupon code on National Singles Day discounts, September 2022 - iVoicesoftĭuplicate File Finder Plus Single License coupon code. Since only the file contents are compared, the truly duplicate files must be found, regardless of whether the file names and modification times are consistent, even the extensions are inconsistent (considering the case of deliberately modifying the extensions for safety), they can be found out also. About Duplicate File Finder Plus Single Licenseĭuplicate File Finder Plus Single License coupon code 35% discount - Duplicate File Finder Plus, Just a faster duplicate files finder with 100% accurate results you will love!Ĭompare whether files are the same at the binary level, that is, compare file contents. Please click or directly to ensure that the discounts is activated successfully.
Duplicate File Finder Plus Single License's descriptionģ5% of discount codes from Duplicate File Finder Plus Single License is valid with 's referral link only.
★★★★★ "Needless to say I am extremely satisfied with the formidable discounts. Please use the coupon code before the end of expiry date to save $10.50. This formidable discounts coupon will expire on September 04. Trisunsoft Coupon Codes: This Promo Code will save you 35% off your order on Duplicate File Finder Plus Single License. Claim discounts code here to save your money immediately! Coupon can be applied for shoping on Trisunsoft. Get discount code from the 2022 Trisunsoft promotions here. National Singles Day is synonymous with formidable events and discounts. This deal ends on September 04 (2 days left).ĭuplicate File Finder Plus Single Licenseĭuplicate File Finder Plus Personal LicenseĬheck more coupons of other editions at the end of this page.
0 notes
Text
Duplicate file cleaner code

#DUPLICATE FILE CLEANER CODE HOW TO#
#DUPLICATE FILE CLEANER CODE UPDATE#
#DUPLICATE FILE CLEANER CODE PORTABLE#
#DUPLICATE FILE CLEANER CODE ANDROID#
#DUPLICATE FILE CLEANER CODE SOFTWARE#
Unwanted images are a clean gallery for clean removal, but duplicate contacts are a clean gallery for clean removal as well as photo cleaner, WhatsApp junk cleaner, duplicate file finder freeware, and duplicate email remover.
#DUPLICATE FILE CLEANER CODE SOFTWARE#
The duplicate checker is the duplicate detector free erase duplicate files using duplicate file cleaner.ĭuplicate File Remover – Duplicates Cleaner is a programme that deletes files from duplicate file software so that images can be cleaned up using photodetection.
#DUPLICATE FILE CLEANER CODE HOW TO#
This is how to detect duplicate files: erase duplicate photos from a file use duplicate apps or cleaner and finder search for duplicate files quickly and use the finest duplicate file finder available for free. Finding and getting rid of them by hand is challenging. In order to save more data or download other apps from the Google Play Store without receiving low storage warnings, this duplicate media remover tool will help you recover a tonne of storage space on your device. Scan your contacts and find duplicate contacts.Īs we use our phones more frequently, random duplicate photo and picture files accumulate in every phone folder, ideally. You will even get notifications for new duplicate files every day. Remove duplicate audios, videos, photos, files and contacts. Identify duplicate and similar photos from your gallery.
#DUPLICATE FILE CLEANER CODE ANDROID#
Now that Android devices have so much storage capacity, we often delete everything we can till the Major Features You can quickly detect identical and similar photographs, movies, and audio files using duplicate files finder, and you may delete them all with a single click. On your Android tablet and phone, it makes it simple to find and delete duplicate files. The majority of our storage is taken up by photos and movies, and if we don’t spot these duplicate files, we risk running out of room for pointless reasons. A strong duplicate file removing app is duplicate file remover. You'll see a popup that displays the results of the process, including the total number of files searched, number of duplicate files that were found and the amount of storage space that can be recovered by deleting said files.Duplicate Files and Contacts Remover Descriptionĭuplicate File Remover – Duplicates Cleaner is an application that cleans up all duplicate media files from your phone’s internal memory, external storage, and SD card. Give it half a minute, and it will finish the scan. The program takes a while to finish the process, especially if the selected folders have hundreds of files. The other options are used to compare the file names, creation date, last modified date and the file type.Ĭlick the Start button to initiate the scan. The first one checks for the file's contents based on their SHA-1 hash values, while the other option takes into account files from multiple folders. There are several rules that you can set for the scan, two of which are pre-enabled match same contents, and match across folders. By default, Dupe Clear will scan inside sub-folders, so if you don't want recursive scanning, you might want to toggle the option. Click the "Add Folder" button and select a directory, you can add multiple folders to be scanned. The main tab is called Search Location, and as the name implies, this is where you select directories that you want the program to scan for duplicate files. It has a minimalist GUI, with 4 tabs and a menu bar. Just tick unnecessary files and remove them. You will see the results of the search for duplicate files on the next tab. Dupe Clear is an open source duplicate file finder for Windows that can help you recover storage space. After running it, specify the folder or disk where you want to search for duplicates, and click on the 'Start' button. But that's not exactly easy to do, who has the time to pour over dozens of folders worth of data? This is why people rely on third-party programs. The solution is pretty obvious, keep one and delete the other.
#DUPLICATE FILE CLEANER CODE PORTABLE#
This happens a lot to, especially when it comes to portable programs. Later you redownload it, and you got two copies now. Maybe you downloaded some application, and moved the installer to a different location. You may also try third-party applications such as CleanMgr+ or PatchCleaner to free up space.Īnother reason why your hard drive could be nearing maximum capacity is due to duplicate files.
#DUPLICATE FILE CLEANER CODE UPDATE#
Try running Windows' Disk Cleanup, you never know how much trash accumulated in the Recycle Bin, and those Windows Update files, those take up a lot of space. Running low on storage space? That's a common issue, especially on low-end laptops you use various programs, browse the internet, and the number of files keep getting higher.
0 notes
Text

slowly and with horror watching the number climb, of commits on the repository for the website i'm building for funsies (i hope nobody was holding their breath, i only have three pages left with no content, but then i have a long list of minor fixes. i also kind of want to go back and put reader-submitted recipes on the other domain, which is now redirecting improperly, but that's my last stretch goal)
file under "things that would not have happened if i listened to my college professors when they said not to push all updates to the main branch" or "things that would not have happened if i had listened to the advice of multiple followers, like 'use a framework' or 'use an ide'" (a lot of these commits were unnecessary, i could have grouped many minor revisions as a much smaller number of commits, if i had been able to view a page live as a local file without using live server in vscode)
like i know i have dug myself into this but. lmao. is there a way to like, refer to html code chunks located in one file, instead of duplicating the same code on every page, i.e. for a navbar? (i know that's a thing, encapsulation, but i don't know how to do it in html) is there some type of automatic css styling reformatter that can rework what i've written in like, a cleaner, more sensible manner? (i don't know if i want to use auto-formatted code, but i want to compare it to what i've written, lol)
like this isn't necessarily the worst practice (building a mockup and then reworking it to be cleaner is good practice, in some sense) but it could have been easier if i had used more of the commonly established best practices, lol (this is kind of an unsurprising result, for having built a website in notepad)
11 notes
·
View notes
Text
Version 428
youtube
windows
zip
exe
macOS
app
linux
tar.gz
I had a good couple weeks working on the taglist code and some other jobs.
If you are on Windows and use the 'extract' release, you may want to do a 'clean' install this week. Extra notes below.
taglists
So, I took some time to make taglists work a lot cleaner behind the scenes and support more types of data. A heap of code is cleaner, and various small logical problems related to menus are fixed. The tag right-click menu is also more compact, quicker to see and do what you want.
The main benefits though are in the manage tags dialog. Now, the '(will display as xxx)' sibling suffix colours in the correct namespace for the sibling, and parents 'hang' underneath all tags in all the lists. It is now much easier to see why a parent or sibling is appearing for a file.
This is a first attempt. I really like how these basically work, but it can get a bit busy with many tags. With the cleaner code, it will be much easier to expand in future. I expect to add 'expand/collapse parents' settings and more sorts, and maybe shade parents a bit transparent, in the coming weeks. Please let me know how it works for you IRL and I'll keep working.
the rest
The main nitter site seems to be overloaded. They have a bunch of mirrors listed here: https://github.com/zedeus/nitter/wiki/Instances
I picked two roughly at random and added new downloaders for them. If you have Nitter subs, please move their 'sources' over, and they should start working again (they might need to do a bit of 'resync' and will complain about file limits being hit since the URLs are different, but give them time). If you would rather use another mirror, feel free to duplicate your own downloaders as well. Thanks to a user who helped here with some fixed-up parsers.
I gave the recently borked grouped 'status' sort in thread watchers and downloader pages another go, and I improved the reporting there overall. The 'working' status shouldn't flicker on and off as much, there is a new 'pending' status for downloaders waiting for a work slot, and the 'file status' icon column now shows the 'stop' symbol when files are all done.
The menu entry to 'open similar-looking files' is now further up on thumbnails' 'open' submenus.
The duplicate filter has its navigation buttons on the right-hand hover window rearranged a bit. It is silly to have both 'previous' and 'next' when there are only two files, so I merged them. You can also set 'view next' as a separate shortcut for the duplicate filter, if you want to map 'flip file' to something else just for the filter.
windows clean install
If you use the Windows installer, do not worry, these issues are fixed automatically for you from now on.
I updated to a new dev machine this week. Some libraries were updated, and there is now a dll conflict, where a dll from an older version is interfering with a new one. As it happens, the library that fails to load is one I made optional this week, so it doesn't ''seem'' to actually stop you from booting the client, but it will stop you from running the Client API in https if you never did it before (the library does ssl certificate generation).
It is good to be clean, so if you extract the Windows release, you may want to follow this guide this week: https://hydrusnetwork.github.io/hydrus/help/getting_started_installing.html#clean_installs
full list
interesting taglist changes:
taglists work way better behind the scenes
when siblings display with the '(will display as xxx)' suffix, this text is now coloured by the correct namespace!
parents now show in 'manage tags dialog' taglists! they show up just like in a write/edit tag autocomplete results list
the tag right-click menu has had a pass. 'copy' is now at the top, the 'siblings and parents' menu is split into 'siblings' and 'parents' with counts on the top menu label and the submenus for each merged, and the 'open in new page' commands are tucked into an 'open' submenu. the menu is typically much tighter than before
when you hit 'select files with these tags' from a taglist, the thumbgrid now takes keyboard focus if you want to hit F7 or whatever
custom tag presentation (_options->tag presentation_, when you set to always hide namespaces or use custom namespace separator in read/search views) is more reliable across the program. it isn't perfect yet, but I'll keep working
a heap of taglist code has been cleaned up. some weird logical issues should be better
now the code is nicer to work with, I am interested in feedback on how to further improve display and workflows here
.
the rest:
added two mirrors for nitter, whose main site is failing due to load. I added them randomly from the page here: https://github.com/zedeus/nitter/wiki/Instances . if you have nitter subs, please move their download source to one of the mirrors or set up your own url classes to other mirror addresses. thanks to a user for providing other parser fixes here
gallery download pages now show the 'stop' character in the small file column when the files are done
gallery download pages now report their 'working' status without flicker, and they report 'pending' when waiting for a download slot (this situation is a legacy hardcoded bottleneck that has been confusing)
thread watchers also now have the concept of 'pending', and also report when they are next checking
improved the new grouped status sort on gallery downloader and watcher pages. the ascending order is now DONE, working, pending, checking later (for watchers), paused
the network request delay after a system resume is now editable under the new options->system panel. default is 15 seconds
the 'wait on files too' option is moved from 'files and trash' to this panel
when the 'just woke' status is active, you now get a little popup with a cancel button to override it
'open similar-looking files' thumbnail menu entry is moved up from file relationships to the 'open' menu
the duplicate filter right-hand hover window no longer has both 'previous' and 'next' buttons, since they both act as 'flip', and the merged button is moved down, made bigger, and has a new icon
added 'view next' to the duplicate filter shortcut set, so you can set a custom 'flip between pair' mapping just for that filter
thanks to a user helping me out, I was able to figure out a set of lookups in the sibling/parent system that were performing unacceptably slow for some users. this was due to common older versions of sqlite that could not optimise a join with a multi-index OR expression. these queries are now simpler and should perform well for all clients. if your autocomplete results from a search page with thumbs were achingly slow, let me know how they work now!
the hydrus url normalisation code now treats '+' more carefully. search queries like 6+girls should now work correctly on their own on sites where '+' is used as a tag separator. they no longer have to be mixed with other tags to work
.
small/specific stuff:
the similar files maintenance search on shutdown now reports file progress every 10 files and initialises on 0. it also has faster startup time in all cases
when a service is deleted, all currently open file pages will check their current file and tag domains and update to nicer defaults if they were pointed at the now-missing services
improved missing service error handling for file searches in general--this can still hit an export folder pointed at a missing service
improved missing service error handling for tag autocomplete searches, just in case there are still some holes here
fixed a couple small things in the running from source help and added a bit about Visual Studio Build Tools on Windows
PyOpenSSL is now optional. it is only needed to generate the crt/key files for https hosting. if you try to boot the server or run the client api in https without the files and without the module available to generate new ones, you now get a nice error. the availability of this library is now in the client's about window
the mpv player will no longer throw ugly errors when you try to seek on a file that its API interface cannot support
loading a file in the media viewer no longer waits on the file system lock on the main thread (it was, very briefly), so the UI won't hang if you click a thumb just after waking up or while a big file job is going on
the 'just woke' code is a little cleaner all around
the user-made downloader repository link is now more obvious on Lain's import dialog
an old hardcoded url class sorting preference that meant gallery urls would be matched against urls before post, and post before file, is now eliminated. url classes are now just preferenced by number of path components, then how many parameters, then by example url length, with higher numbers matching first (the aim is that the more 'specific' and complicated a url class, the earlier it should attempt to match)
updated some of the labelling in manage tag siblings and parents
when you search autocomplete tags with short inputs, they do not currently give all 'collapsed' matching results, so an input of 'a' or '/a/' does not give the '/a/' tag. this is an artifact of the new search cache. after looking at the new code, there is no way I can currently provide these results efficiently. I tested the best I could figure out, but it would have added 20-200ms lag on all PTR searches, so instead I have made a plan to resurrect an old cache in a more efficient way. please bear with me on this problem
tag searches that only include unusual characters like ? or & are now supported without having to lead the query with an asterisk. they will be slower than normal text search
fixed a bug in the 'add tags before import' dialog for local imports where deleting a 'quick namespace' was not updating the tag list above
.
windows clean install:
I moved to a new windows dev machine this week and a bunch of libraries were updated. I do not believe the update on Windows _needs_ a clean install this week, as a new dll conflict actually hits the coincidentally now-optional PyOpenSSL, but it is worth doing if you want to start using the Client API soon, and it has been a while, so let's be nice and clean. if you extract the release on Windows, please check out this guide: https://hydrusnetwork.github.io/hydrus/help/getting_started_installing.html#clean_installs
the Windows installer has been updated to remove many old files. it should now do clever clean installs every week, you have nothing to worry about!™
.
boring db breakup:
the local tags cache, which caches tags for your commonly-accessed hard drive files, is now spun off to its own module
on invalid tag repair, the new master tags module and local tags cache are now better about forgetting broken tags
the main service store is spun off to its own module. several instances of service creation, deletion, update and basic fetching are merged and cleaned here. should improve a couple of logical edge cases with update and reset
.
boring taglist changes:
taglists no longer manage text and predicates, but a generalised item class that now handles all text/tag/predicate generation
taglist items can occupy more than one row. all position index calculations are now separate from logical index calculations in selection, sizing, sorting, display, and navigation
all taglist items can present multiple colours per row, like OR predicates
items are responsible for sibling and parent presentation, decoupling a heap of list responsibility mess
tag filter and tag colour lists are now a separate type handled by their own item types
subordinate parent predicates (as previously shown just in write/edit autocomplete result lists) are now part of multi-row items. previously they were 'quiet' rows with special rules that hung beneath the real result. some related selection/publish logic is a bit cleaner now
string tag items are now aware of their parents and so can present them just like autocomplete results in write/edit contexts
the main taglist content update routines have significantly reduced overhead. the various expansions this week add some, so we'll see how this all shakes out
the asynchronous sibling/parent update routine that populates sibling and parent data for certain lists is smarter and saves more work when data is cached
old borked out selection/hitting-skipping code that jumped over labels and parents is now removed
'show siblings and parents' behaviour is more unified now. basically they don't show in read/search, but do in write/edit
a heap of bad old taglist code has been deleted or cleaned up
next week
This was a big couple of weeks. Setting up the new dev machine--I replaced my six year old HP office computer with a nice mini-pc with an SSD--worked out great, but there were some headaches as always. The taglist work was a lot too. I'll take next week a little easier, just working misc small jobs.
1 note
·
View note